Intended audience: This article is written for senior, staff, and principal engineers who design or build trading infrastructure, low-latency systems, or distributed deterministic platforms. It assumes working familiarity with the JVM, FIX protocol, concurrency primitives, and the basic shape of electronic markets. Readers new to these topics will find it dense; readers experienced with them should find the depth appropriate.
Reference implementation: The complete NitroJ Exchange source — including specifications, implementation plans, migration notes, release-evidence bundles, and the platform code referenced throughout this article — is available at github.com/rueishi/nitroj-exchange.
What an institutional trading system actually is
An institutional trading system is software that places, modifies, and reconciles orders on financial markets on behalf of professional traders, market makers, hedge funds, banks, or proprietary trading firms — at a scale, latency, and reliability standard that retail trading software cannot meet.
NitroJEx is not a trading bot or execution script. It is a deterministic execution platform — single-writer, replay-correct, evidence-gated, and built on the same architectural patterns used by institutional firms privately. The distinction matters because most public discussions of “trading systems” conflate the two, and the engineering decisions that follow from each starting point are fundamentally different.
It is helpful to be specific about what “institutional grade” means, because the term is often used loosely. An institutional trading system must be:
- Fast. Decisions must execute in microseconds end-to-end during steady state. Garbage collection pauses, lock contention, allocation-driven cache misses, and unbounded data structures are not acceptable on the critical path. Tail latency matters as much as average latency, because a single multi-millisecond stall during a market move produces stale quotes that lose real money. This is what people mean by “low-latency Java” or “zero-GC trading system” — terms that describe a coordinated discipline, not a tuning checklist.
- Deterministic. Given the same ordered sequence of inputs, the system must produce the same ordered sequence of outputs. This is the foundation for replayable testing, post-trade analysis, regulatory audit, and cluster failover. A system whose behavior depends on wall-clock timing or thread scheduling cannot be trusted to behave the same way twice.
- Correct under adversarial conditions. Real venues drop messages, deliver duplicates, reorder responses, disconnect mid-session, halt trading, and produce inconsistent feeds. Real markets gap, lock limit-up, and trigger circuit breakers. The system must handle all of this without corrupting its own state.
- Recoverable. When a process crashes or a leader fails over, the system must reconstruct its state correctly from persisted logs and snapshots — and continue trading without missing fills, double-counting positions, or losing track of working orders.
- Auditable. Every decision the system made must be reproducible from recorded inputs. Regulators, risk committees, and post-mortem investigations all rely on this property.
- Risk-bounded. Every order leaving the system must have passed through a pre-trade risk check that can refuse it. Position limits, notional limits, order-rate limits, and a kill switch that operates in under a second are not optional features; they are foundational.
- Maintainable across years of evolution. Venues come and go, FIX dialects change, regulations tighten, new asset classes emerge, new strategies get added. The architecture must allow these changes without rewriting the core.
These properties are coupled. You cannot achieve correctness without determinism. You cannot achieve recoverability without correctness. You cannot achieve audit defensibility without recoverability. You cannot achieve fast execution under load without bounded memory behavior. The whole structure must be designed together, from the start, because retrofitting any of these later is dramatically more expensive than designing them in.
The factors below are not “best practices.” They are the load-bearing structural decisions that determine whether the system holds together at scale, and the techniques real systems use to address them. The patterns described here are widely used in production at investment banks, proprietary trading firms, and HFT shops; most of those implementations are private. NitroJEx — a Java 21 platform built on Aeron, SBE, and Artio FIX, targeting multi-venue cryptocurrency market making and statistical arbitrage — is an open-source reference implementation that documents and attempts these patterns rigorously, with explicit boundaries between what is architecturally designed, what is benchmark-proven, and what remains on the roadmap. We use it throughout this article to ground the abstract patterns in concrete code and configuration.
The high-level shape of the system is a separated gateway-cluster topology with four orthogonal plugin axes. We will spend the rest of the article unpacking each piece:
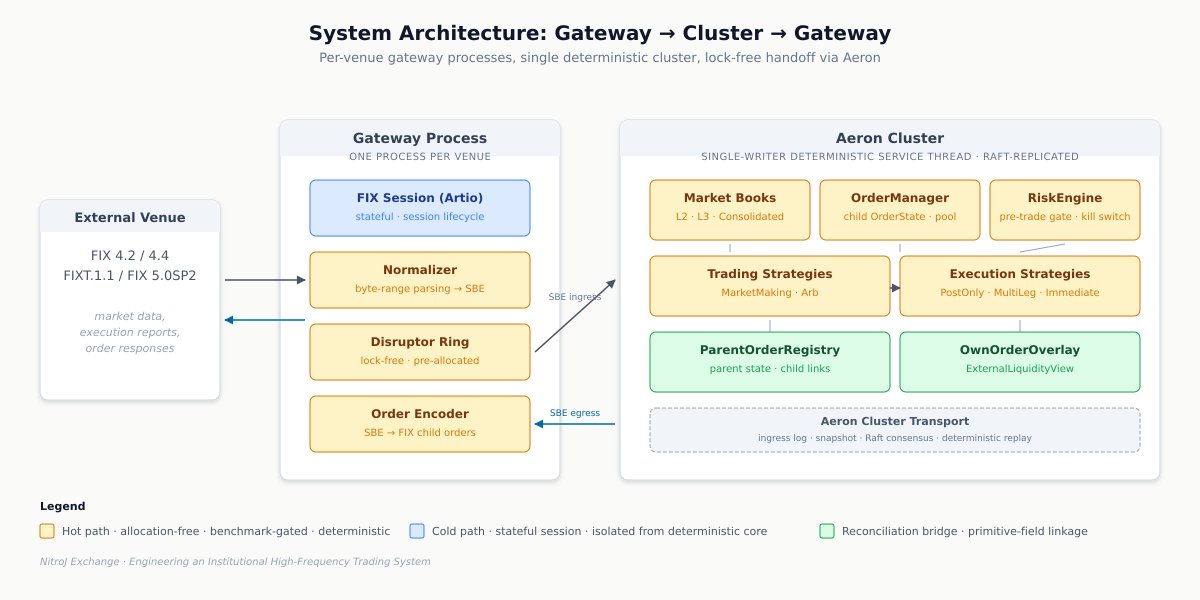
To make this concrete before we start unpacking it, here is the path of a single market-data tick through the system, end to end:
The venue publishes a market-data update over FIX. The gateway’s FIX session — running on a pinned core, isolated from the OS scheduler — receives the bytes and hands them to the normalizer. The normalizer parses the FIX message directly from byte buffers, never materializing a String, and produces a primitive-typed SBE event. The event crosses into the cluster through a Disruptor ring buffer (no allocation, no locks) and then over Aeron to the cluster service thread. The cluster thread updates the relevant VenueL2Book or VenueL3Book, which in turn updates the ConsolidatedL2Book and the ExternalLiquidityView. A trading strategy — MarketMakingStrategy, say — observes the change, recomputes its fair value and inventory skew, and decides to refresh its quote. It submits a ParentOrderIntent to the execution-strategy engine. PostOnlyQuoteExecution receives the intent, encodes a child order, and routes it through the risk engine. The risk engine validates against position limits, notional limits, and self-cross checks, and either approves or rejects in sub-microsecond time. On approval, the child order is encoded as an SBE command, written to a reusable buffer, and offered through Aeron to the gateway. The gateway translates the SBE command back into a FIX NewOrderSingle and sends it to the venue. The venue eventually responds with an ExecutionReport, which traces the same path in reverse — normalized at the gateway, delivered to the cluster, applied to the child OrderState through OrderManager, propagated to the parent state through ParentOrderRegistry, attributed to the originating strategy by parentOrderId, and reflected in PortfolioEngine. The same ordered SBE event stream replayed against a fresh cluster — from disk, from snapshot, or from a Raft follower catching up — produces bit-identical state evolution. Every decision is reproducible. Every dollar is accounted for.
Each architectural decision in the rest of this article exists to make some part of that flow correct, fast, deterministic, recoverable, or auditable. The shape of the system is the answer to a long list of “what could go wrong here” questions; the rest of the article walks through the questions and the answers.
Core architectural moves
For readers who want the shape of the argument before the detail, here is what an institutional-grade trading platform actually requires. Each of these is unpacked in the sections that follow.
- A statically-enforced hot-path / cold-path boundary. Hot paths are allocation-free, deterministic, and bounded; cold paths are allowed to allocate. The boundary is enforced by ArchUnit, not by hope.
- Four orthogonal plugin axes. Wire protocol, venue, trading strategy, and execution strategy extend independently. Any feature touching all four is a design failure.
- L2 and L3 modeled distinctly. Per-venue and consolidated views are separate objects; L2 is derived from L3 deterministically; queue position is a real concern.
- Three layers of state, never confused. Public market state, own-order state, and parent-intent state each have their own authoritative source — venue feed, execution reports, and parent registry respectively. Inter-layer attribution is a primitive field, never an auxiliary map.
- Idempotent state transitions. Every event must produce identical state if applied twice. Duplicate execution reports are a fact of life, not a bug.
- Self-liquidity awareness. Arbitrage works against external executable liquidity, not gross venue depth. Venue-native STP is an emergency brake, not the primary defense.
- A deterministic memory model. GC is nondeterminism; allocation is hidden latency variance. Zero-allocation steady-state hot paths are a structural property, not an optimization.
- JIT warmup as a deployment phase. The JVM does not run at peak speed when it starts. Warmup, profile capture, and AOT techniques bring the system to steady-state before it accepts production traffic.
- Java with discipline as a deliberate platform choice for the deterministic CPU work. Disciplined Java approaches C++ on the trading hot path; FFM (not JNI) connects native code at near-native call cost; the architect picks the right substrate per workload — Java for deterministic CPU work, C++/CUDA via FFM for GPU-bound quant compute and hardware-near integrations.
- Hardware-aware deployment. CPU pinning, NUMA awareness, kernel tuning, and Aeron-specific configuration determine whether application-level latency claims survive contact with reality.
- A single-writer deterministic cluster. All hot-path state mutation happens on one thread, in strict order, with full replay support.
- Pre-trade risk that gates every order. Bounded, fast, configurable, kill-switch-equipped, with reject reasons as codes.
- Documented state machine invariants. Every transition is explicitly legal or explicitly rejected; cumulative consistency, fill bounds, and idempotency are tested against every reachable state.
- Layered testing with a hard pre-UAT gate. Unit, integration, simulator, live-wire, deterministic replay, snapshot/load, JMH allocation, and latency histogram tiers all pass before the system touches a real venue.
- Operational runbooks. Explicit procedures for parent stuck, child stuck, hedge rejected, post-only reject loops, capacity exhaustion, and rollback. Each has explicit conditions, explicit actions, and explicit kill-switch escalations.
- The discipline of evidence. Architectural claims, empirical claims, and roadmap claims are kept separate. Every release claim has an evidence artifact behind it.
If your platform misses any of these, the gap will eventually surface — usually under load, often expensively. The rest of the article walks through each in detail.
1. The two time domains: hot path versus cold path
The single most important conceptual move in any low-latency trading system is the explicit separation of the hot path from the cold/control path.
The hot path is the steady-state event flow that processes every market-data tick, every execution report, every risk decision, every strategy evaluation, every order command. It runs millions of times per second under load, must be deterministic, must be bounded in latency, and — for any institutional system — must be allocation-free after warmup. The cold/control path covers everything that happens at startup or out of band: configuration loading, plugin registry construction, admin tooling, REST polling, operator diagnostics, the test harness. Cold paths are allowed — encouraged, even — to use general-purpose collections, exceptions, formatted strings, and idiomatic Java. Trying to enforce zero allocation across the entire codebase is wasted effort; the discipline only matters where it actually pays off.
Key Principle: Define the hot-path boundary explicitly, document it, and enforce it statically. Every later decision flows from this one.
The boundary is what matters. Once defined, every later decision flows from it: which collections you use, how you handle errors, how you log, how you parse incoming protocols. NitroJEx makes the hot-path surface explicit: FIX market-data parsing, FIX execution-report parsing, SBE encode/decode, the gateway-to-cluster handoff, venue and consolidated book mutation, the own-order overlay, the external-liquidity view, the order manager state machine, the risk engine decision, the strategy dispatch, the parent-order registry, the execution-strategy engine, and order command encoding. Cold-path data must not leak into hot-path state without explicit conversion to compact primitive form first. NitroJEx enforces this for its REST polling integration: REST data uses heap-allocating JSON parsing, but is confined to the venue gateway and crosses into cluster state only as primitive-typed events, never as JSON objects.
Two specific rules elevate this from guideline to contract. First, the forbidden API list on hot paths is enumerated and statically enforced: new String(...), Long.toString(...), String.format(...), per-event new byte[], HashMap mutation with object keys, List growth, boxed Long/Integer values, exception construction for expected data-quality failures, formatted logging for expected failures, and wall-clock reads outside the deterministic cluster clock. NitroJEx uses ArchUnit tests that fail the build if forbidden patterns appear in declared hot-path packages. Second, the required failure-reporting style is also explicit: counters, status codes, and safe drops — never thrown exceptions for expected hot-path conditions. An unknown symbol or malformed tick increments a counter and continues; it does not allocate a RuntimeException or format a log message.
Before writing a single hot-path line, decide which paths are hot, document the boundary, spell out the forbidden APIs, and spell out the failure-reporting style. Every later decision flows from this one.
2. Plugin architecture: orthogonal extension axes
A common failure mode in trading platforms is conflating concerns that should be independent: the wire protocol (FIX 4.2 vs 4.4 vs FIXT.1.1/FIX 5.0SP2 vs proprietary binary), the venue (Coinbase vs Binance vs CME vs an interbank ECN), the trading strategy (market making vs arbitrage), and the execution algorithm (post-only quoting vs IOC sweeping vs TWAP). When these are conflated, every new venue forces a fork of strategy code, every new strategy forces a fork of session-handling code, and the system slowly becomes unmaintainable.
A serious platform separates these into independent extension axes. NitroJEx organizes them as four:

Protocol plugins own wire-level mechanics only: FIX BeginString, DefaultApplVerID, the dictionary class, generated codec packages, session configuration. Each FIX version generates its codecs into a unique Java package, so multiple versions coexist in one build without symbol collision.
Venue plugins own venue-specific behavior: authentication and logon customization, proprietary tags, order-entry policy, execution-report normalization, market-data enrichment, venue capabilities. The contract looks roughly like:
interface VenuePlugin {
String id();
VenueCapabilities capabilities(VenueConfig venue);
VenueLogonCustomizer logonCustomizer(CredentialsConfig credentials);
VenueOrderEntryAdapter orderEntryAdapter(...);
ExecutionReportNormalizer executionReportNormalizer();
MarketDataNormalizer marketDataNormalizer(...);
CredentialsConfig resolveCredentials(...);
}
Coinbase code lives only in NitroJEx’s Coinbase venue plugin. It does not seep into the FIX layer or the cluster layer. Adding Binance later means writing a BinanceVenuePlugin and registering it; nothing else changes.
Trading strategy plugins decide what positions the firm wants to hold. They consume normalized market views, external-liquidity views, portfolio state, and risk state; their output is a declarative parent-order intent.
Execution strategy plugins decide how a parent intent is worked into child orders at venues. They own all child-order encoding, cluster offers, cancel/replace lifecycle, leg sequencing, leg timeouts, partial-leg imbalance hedging, and post-only retry behavior.
The discipline this enforces is a four-axis test: any new feature should belong cleanly to exactly one of {protocol, venue, trading-strategy, execution-strategy}. If a proposed change touches all four, the design is wrong.
The trading-strategy / execution-strategy split is worth pausing on, because most systems get it wrong. Consider a market-making class that computes a fair price from the book, applies inventory skew, decides quote sizes — and also encodes new-order and cancel commands directly, tracks live client order IDs, manages cancel-and-replace timing, handles post-only rejects with tick-deeper retries, and applies rejection cooldowns. That single class is doing two distinct jobs: deciding what to quote, and deciding how to work the resulting orders. As long as you only need one execution behavior under each trading intent, this entanglement is harmless. The pain shows up the moment you want a second execution behavior under the same trading intent — for example, post-only quoting in calm markets and aggressive crossing-the-spread quoting in fast markets, without forking the strategy class. The only clean answer is to split the layers.
NitroJEx’s split looks like:
interface ExecutionStrategy {
void init(ExecutionStrategyContext ctx);
void onParentIntent(ParentOrderIntentView intent);
void onMarketDataTick(int venueId, int instrumentId, long clusterTimeMicros);
void onChildExecution(ChildExecutionView execution);
void onTimer(long correlationId);
void onCancel(long parentOrderId, byte reasonCode);
}
Trading strategies submit declarative ParentOrderIntent SBE messages through ctx.executionEngine().submit(...). They never see SBE encoders. Execution strategies own the encoding and the lifecycle. Per-instance and per-instrument pairing is configuration, not code:
[[strategy]]
id = "mm-btc-coinbase"
type = "MarketMaking"
executionStrategy = "PostOnlyQuote"
Two instances of the same market-making class can run side by side with different execution behaviors. Default compatibility (MarketMaking → PostOnlyQuote, Arb → MultiLegContingent) is validated at startup; incompatible pairings fail before any market data is processed.
3. Market data: why L2 and L3 are not interchangeable
Trading decisions depend on how accurately the system represents the market. A casual observer often assumes Level 2 (price-aggregated) and Level 3 (order-by-order) market data are different views of the same thing and that one can substitute for the other. They cannot, and a serious platform has to model both.
Level 2 represents price-level liquidity: at price P on side S, there is total visible quantity Q. It is compact, sufficient for spread and top-of-book decisions, and is the natural unit for cross-venue consolidation.
Level 3 represents order-level liquidity: each individual resting order is observable, with a venue order ID, side, price, size, and (depending on venue) timestamp. L3 is heavier on the wire and in memory, but it enables two things L2 cannot: queue-position estimation for passive quoting, and exact reconciliation between the public book and your own resting orders.
NitroJEx maintains three distinct book types. VenueL2Book is the per-venue price-level book. VenueL3Book is the per-venue order-level book, populated only for L3 venues. ConsolidatedL2Book is the cross-venue aggregate L2, used for fair-value estimation, hedging decisions, adverse-selection detection, and arbitrage. For L3 venues, NitroJEx derives L2 from the L3 state and feeds that into the consolidated view, so the consolidated book is always L2 regardless of underlying feed types.
These books use bounded primitive structures — order lookup by venue order ID via fingerprint-keyed bounded storage with byte-comparison collision resolution, level aggregation in arrays indexed by (venueId, instrumentId, side), derivation logic that allocates nothing after warmup. JMH benchmarks publish allocation evidence proving this under documented capacity limits.
A real-system caveat worth flagging: strategies that quote passively on L3 venues benefit enormously from queue-position estimation. Given the depth ahead of your order at acceptance time, plus subsequent trades and cancels at that level, what is your fill probability? The substrate to compute this exists in any L3-aware platform; turning it into an explicit QueuePositionEstimate view that strategies query is a natural extension. Latency-adjusted views — “what will the book be when my order reaches the matching engine” — are a related extension that grafts cleanly onto the existing book objects.
4. State separation: market state, own-order state, and intent state are different things
This is the principle that separates serious trading platforms from naive ones, and it generalizes across multiple layers:
Key Principle: Market books are not the source of truth for your own orders. Execution reports are. Child orders are not the source of truth for parent intents. The parent registry is.
Every venue feed has latency, every venue feed can drop or reorder messages, and every venue feed can disagree transiently with the venue’s own internal order state. If you treat the public market-data feed as authoritative for your own orders, you will eventually act on a quote you no longer have, hedge a fill that hasn’t happened, or attempt to cancel an order the venue believes you’ve already canceled. None of these failure modes are theoretical; they are the standard ways an HFT system loses money.
NitroJEx separates the layers completely. The public market view is owned by the venue and consolidated book objects. The system’s own working orders are owned by OrderManager, whose state transitions only on execution reports. Fills, cancels, rejects, and replaces flow through OrderManager and update PortfolioEngine for position and RiskEngine for limit checks. Parent-order intents (the trading strategy’s declarative requests) are owned by a separate ParentOrderRegistry. Each layer’s state is authoritative for its own concerns and nothing else.
The bridges between layers are explicit reconciliation objects. OwnOrderOverlay answers “which of these public orders are mine?” ExternalLiquidityView answers “what gross liquidity is available minus my own visible resting orders?” These objects are queried by strategies that need to reason about external liquidity — the liquidity available to trade against — without confusing it with their own quotes.
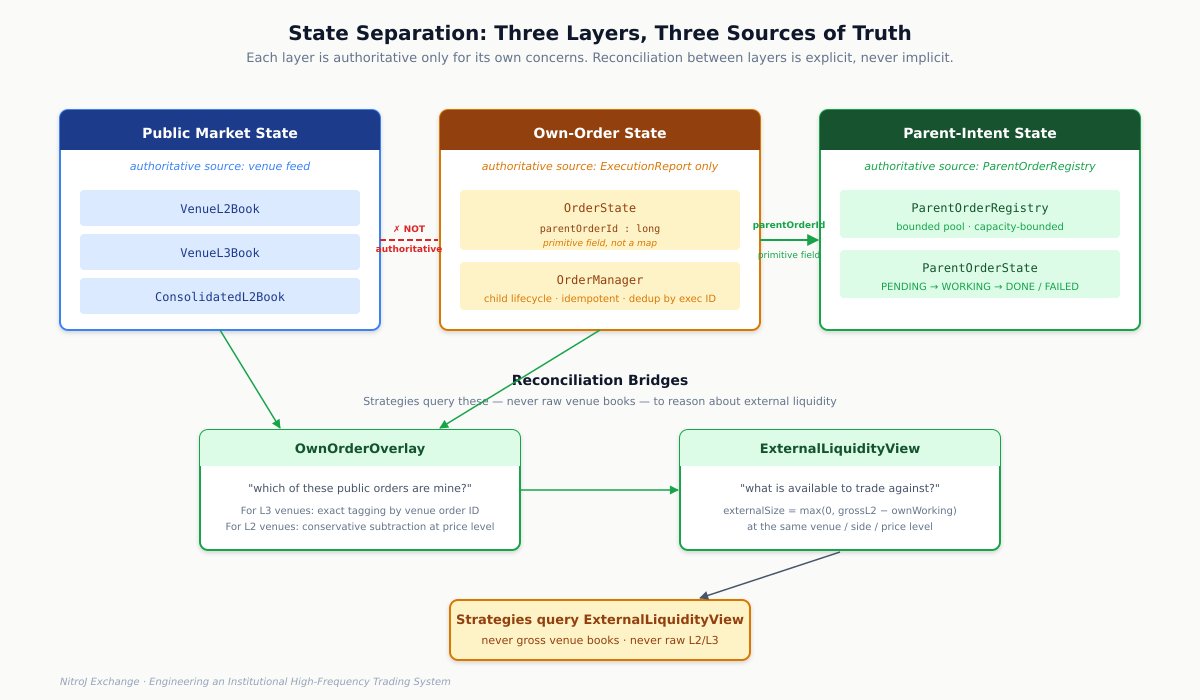
Three distinct layers, each authoritative for its own concerns. The links between them are explicit reconciliation objects (green) and a primitive parentOrderId field on OrderState — never an auxiliary map.
The link between child orders and parent intents is not a separate map. It lives directly on OrderState.parentOrderId as a primitive long field, and demultiplexing on the hot path uses it directly. A general-purpose auxiliary map from child to parent is forbidden. This sounds like a small architectural rule, but it has two large consequences. First, dispatch is allocation-free and constant-time. Second, parent reconciliation after any kind of recovery is straightforward: for any child whose parentOrderId doesn’t match an active parent in the registry, you have unreconciled risk and the kill switch stays active until the operator clears the condition. The same pattern generalizes: the link between layers should be a primitive field on the lower-layer state object, never an auxiliary map.
A related invariant deserves explicit treatment: idempotent execution-report handling. Every FIX session can deliver duplicate execution reports through resend requests, sequence-gap recovery, or operator-driven message replay. A naive OrderManager that adds the fill quantity each time it receives an ExecutionReport with the same exec ID will double-count fills and corrupt position state. NitroJEx’s OrderManager requires bounded duplicate-execution-ID detection on the hot path: every execution event is checked against a bounded fingerprint store of recent exec IDs, duplicates are dropped through a counter, and the state machine is mathematically identical whether the venue sent the message once or three times.
Key Principle: Every normalized event must be safe to replay. Idempotency is one of the hardest properties to retrofit and one of the cheapest to design in.
The architectural lesson generalizes: every dual-source data domain in a trading system needs an explicit reconciliation object, every event-driven state transition must be idempotent, and the link between layers must be a primitive field — never an auxiliary map.
5. Self-trade prevention and the own-liquidity trap
The naive arbitrage strategy looks like this: scan the consolidated L2 book; if the best bid on Venue A exceeds the best ask on Venue B by more than fees and slippage, send a buy on B and a sell on A. This algorithm has destroyed many small trading firms.
The reason is that your own quotes are part of the market data you are consuming. If your market maker is quoting on Venue A at $100.00 bid for 1 BTC, and your arbitrage strategy sees that bid as external liquidity to trade against, you can route a sell to Venue A that crosses your own bid. You have not arbitraged anything; you have paid two sets of fees to move inventory between two of your own pockets, and you may have triggered a self-trade that the venue penalizes you for.
A serious platform addresses this systematically. Arbitrage must distinguish three views:
- Gross venue L2: all venue-published visible liquidity.
- Own working orders: your authoritative state from
OrderManager. - External executable L2: gross L2 minus your own visible resting liquidity, where identifiable or conservatively estimable.
Arbitrage must use the third view, never the first. For L3 venues where reliable order-ID matching is available, NitroJEx tags own orders in the L3 book exactly. For L2 venues where exact identification isn’t available, the conservative approximation is externalSize = max(0, grossL2Size - ownWorkingSize) at the same venue/side/price. This sometimes underestimates the true external liquidity, which is the right direction to err in.
Beyond external liquidity, NitroJEx requires a pre-trade self-cross check: before sending an arbitrage leg, the strategy verifies that the new order would not cross any of the firm’s own resting orders on the same venue/instrument. If it would, the strategy must take an explicit action — skip, reduce size, cancel-then-trade, or rely on venue-native STP — not silently send the order and hope.
Finally, venue-native self-trade prevention is configured at the order-entry policy level. Coinbase’s STP tags are added in the venue plugin’s order-entry policy, not in generic strategy code. STP is treated as an emergency brake — it does not replace the strategy-level external-liquidity and self-cross checks. A platform that relies solely on venue STP has outsourced its risk management to an external system whose rules can change without notice.
The general principle: in a multi-strategy multi-venue platform, your own activity is part of the environment your strategies observe. Modeling this honestly is non-negotiable.
6. The deterministic memory model: zero allocation on the hot path
Garbage collection is the single largest source of unpredictable latency on the JVM. A young-generation GC pause measured in milliseconds, occurring at the wrong moment during a market-data burst, produces stale quotes that lose money. The defense is structural rather than tactical: if you do not allocate, you do not collect.
Key Principle: GC is nondeterminism. Allocation is hidden latency variance. Hot paths must be allocation-free; cold paths are allowed to allocate. This is a memory model, not a performance optimization.
This is the deterministic memory model, and it sits alongside determinism itself as a foundational property — not an optimization layered on top of an otherwise normal Java application, but a structural constraint that shapes every hot-path data type, every collection choice, every error-handling decision.
The techniques are well known in the low-latency Java community, but applying them as a coordinated, evidence-gated discipline is not:
Primitive collections and arrays indexed by ID. Hot-path state moves away from HashMap<String, ...> and toward arrays indexed by (venueId, instrumentId, side). Where maps are unavoidable, primitive int/long-keyed maps replace boxed-key maps. The rule is: if your map’s key is a String or a record, your map is on the wrong path.
Scaled long arithmetic. Prices, sizes, quantities, notionals, and fees are stored as scaled longs, never BigDecimal or double. This eliminates allocation, removes floating-point ambiguity from money math, and is dramatically faster. A price of 100.25 stored as 10025 with implicit scale of 2 is a primitive long; it allocates nothing and compares in a single CPU instruction.
Reusable mutable context objects and flyweight views. A FIX message becomes a MarketDataContext mutated in place, not allocated per message. Strategies and execution strategies receive references to these contexts and must not retain them past the call. NitroJEx’s ParentOrderIntentView and ChildExecutionView are flyweights over the underlying SBE buffers — they expose typed accessors without allocating.
Direct buffer parsing. All hot-path FIX parsing is byte-range based; no normal-path String materialization. Decimals are parsed straight to scaled longs from byte ranges, FIX enum tags map from raw byte/char values, symbols resolve through a byte-based registry lookup that returns instrument IDs without allocating Strings.
Bounded venue order ID and execution ID identity. Stored as (venueId, instrumentId, hash, fixed-byte-storage, length) with byte-comparison collision resolution. Venue-assigned text IDs are common; treating them as String keys in production hot paths is a defect.
Counters instead of exceptions and logs. An unknown symbol or malformed tick increments a counter and drops the message; it does not construct a RuntimeException or format a log message. Operator visibility comes from cold monitoring code that periodically reads counter snapshots.
Bounded preallocated state with explicit capacity behavior. Every hot-path structure declares its capacity. When capacity is exceeded, the structure rejects/drops with a counter — never resizes, never allocates, never throws. A trading system with unbounded data structures on the hot path is a trading system with unbounded GC behavior under load.
The deterministic memory model has practical consequences for the GC choice itself. For steady-state production, low-pause collectors like ZGC or Shenandoah provide bounded pause times that complement (not replace) zero-allocation discipline. For burn-in and benchmark scenarios, Epsilon GC (-XX:+UseEpsilonGC) is sometimes used: it allocates but never collects, so the JVM crashes if your code allocates beyond the heap, providing absolute proof that hot paths are allocation-free under load. The discipline is: design the hot path to allocate nothing, configure the GC so allocation is visible if it happens, and prove the invariant continuously through benchmarks.
7. JIT warmup, profile capture, and ahead-of-time compilation
A JVM-based trading system has a problem most application servers can ignore: the JVM does not run your code at peak speed when it starts. The HotSpot JIT compiler optimizes code based on observed execution profiles, and those profiles take time and traffic to develop. A method called a few hundred times runs in interpreted mode. A method called several thousand times triggers C1 (client) compilation with light optimizations. A method called tens of thousands of times in a stable shape triggers C2 (server) compilation with aggressive inlining, escape analysis, vectorization, and speculative deoptimization.
For a web server, the gap between cold and hot doesn’t matter much — cold startup is amortized over hours of uptime. For a trading system, the first few minutes after deployment can be exactly when you need peak performance, and a JIT compilation triggered mid-burst produces a latency spike that costs real money. Worse, deoptimization events — when the JIT discovers that a speculative assumption was wrong and falls back to the interpreter while it recompiles — produce multi-millisecond stalls at unpredictable moments.
Key Principle: The JIT must reach steady state before the system handles production traffic. Warmup is not “optional preparation” — it is part of the deployment process, and the warmup profile itself is an artifact worth capturing and reusing across restarts.
A serious JVM-based trading platform addresses this through a coordinated set of techniques.
Deliberate warmup phase
The simplest and most important technique: before the system is allowed to handle production traffic, run a warmup phase that exercises every hot-path code shape with realistic inputs at production rates. Replay a recorded segment of historical market data through the gateway and cluster, submit synthetic parent intents through every execution strategy, exercise every order-state transition, and burn the resulting profile into the JIT.
The warmup phase typically lasts 5-30 minutes depending on the platform. It runs as part of process startup, before the system is registered as a healthy member of the cluster or accepts a leader role. JFR (Java Flight Recorder) captures the warmup, both as an observability artifact and as a sanity check — you want to see the C2-compiled methods listed in JFR’s compilation events before you accept production traffic.
What “every hot-path code shape” means in practice is the trickiest part. Code that the warmup phase doesn’t exercise will JIT-compile during production traffic. A market-making strategy that warmup exercises only against L2 venues will trigger fresh compilation when an L3 venue first delivers data. A risk engine warmed up only with approval cases will compile its rejection branches under live load. The warmup design has to enumerate the code shapes deliberately, not assume that “running for 10 minutes” produces complete coverage.
Tiered compilation thresholds
The default tiered compilation thresholds are tuned for typical Java workloads — web applications, batch jobs, microservices. They are not tuned for trading systems. The defaults wait for tens of thousands of method invocations before triggering C2 compilation, which is fine when steady-state is hours long but wasteful when you have a 30-minute warmup window.
Two adjustments that institutional shops typically make:
-XX:+TieredCompilation
-XX:TieredStopAtLevel=4 # ensure C2 is reached, not just C1
-XX:CompileThreshold=1500 # lower than the 10000 default
-XX:Tier3CompileThreshold=500 # accelerate C1 → C2 progression
-XX:Tier4CompileThreshold=5000 # accelerate to C2
-XX:ReservedCodeCacheSize=256m # ensure code cache doesn't fill
-XX:+UseCodeCacheFlushing # but flush old code if it does
The exact numbers depend on the workload and warmup design; the principle is to compile aggressively during the deliberate warmup phase rather than lazily over the first hours of production. A code cache that fills up in production triggers JIT-compilation eviction and recompilation under load, which is precisely the failure mode warmup is meant to prevent — so size the code cache generously and monitor its usage.
Class Data Sharing (CDS) and AppCDS
Class loading is a real cost at startup. The JVM has to read class files, verify them, resolve references, and initialize them — work that is repeated on every restart unless you cache it. Class Data Sharing (CDS) and its application-level extension Application Class Data Sharing (AppCDS) let you pre-package the loaded class metadata into a shared archive that subsequent JVM startups memory-map directly.
The workflow:
# 1. First run: capture which classes get loaded
java -XX:DumpLoadedClassList=app.classlist -jar nitrojex-cluster.jar warmup
# 2. Build the archive from that class list
java -Xshare:dump \
-XX:SharedClassListFile=app.classlist \
-XX:SharedArchiveFile=app.jsa \
-jar nitrojex-cluster.jar
# 3. Subsequent runs: use the archive
java -XX:SharedArchiveFile=app.jsa -jar nitrojex-cluster.jar
For a typical trading-platform process, AppCDS reduces startup time by 30-50% and reduces memory footprint by sharing class metadata across JVM instances on the same host. The savings are largest for processes with many dependencies (Aeron, Artio, Agrona, the SBE generated codecs all pull in significant class graphs).
Profile-Guided Optimization with cached profiles
JDK 21+ supports cached compilation profiles that persist JIT decisions across JVM restarts. The first run captures the profile; subsequent runs start with the JIT already knowing which methods to compile aggressively, which call sites are monomorphic, which branches are hot, and which speculative optimizations are safe. The relevant flags vary by JDK version and vendor; for OpenJDK 21+:
-XX:+UnlockExperimentalVMOptions
-XX:+UseAOTLinkResolver # if AOT-resolved methods are present
-XX:+RecordTraining # capture training data
-XX:TrainingFile=app.training # write training profile
For subsequent runs:
-XX:ReplayDataFile=app.training # replay profile on startup
The technique is sometimes called “JIT preheating” or “trained JIT.” It moves the warmup work from production-restart time to a one-time training step, and it materially reduces the warmup window required after each restart.
Ahead-of-time compilation
For the most demanding deployments, JDK 24’s Project Leyden produces ahead-of-time compiled native code via jaotc (or the newer Leyden tooling) that bypasses the JIT entirely for designated methods. The trade-off is real: AOT-compiled code runs immediately at full speed but cannot benefit from runtime profile information, so it’s typically slower in steady-state than well-warmed C2 code. The institutional pattern is hybrid: AOT-compile the most latency-sensitive cold paths (startup, config parsing, the first execution-report handling) so the system reaches usable performance immediately, while letting C2 compile the steady-state hot path with full profile guidance.
GraalVM Native Image is a separate ecosystem that compiles the entire JVM application into a native binary. It eliminates JIT entirely, eliminates GC entirely (with --gc=epsilon), and produces millisecond startup. For trading systems it’s a real option for components where startup latency dominates (gateway processes that may need rapid restart) but it sacrifices the C2-quality steady-state optimization that’s typically worth more than fast startup.
Deoptimization avoidance
The flip side of speculative JIT optimization is deoptimization: when the JIT discovers a runtime fact that contradicts a speculative assumption, it falls back to the interpreter and recompiles. Deoptimization events are visible in JFR as Deoptimization events and produce stalls of hundreds of microseconds to single-digit milliseconds. They’re particularly insidious because they happen rarely in testing (where the speculative assumption holds) and frequently in production (where edge cases break it).
The defensive techniques:
- Monomorphic call sites. Avoid polymorphic dispatch on hot paths. If a hot-path interface has multiple implementations, the JIT will inline only one and deoptimize when it sees another. Either keep the interface monomorphic on the hot path, or accept the cost.
- Stable types. Avoid
instanceofchecks and downcasts on hot paths. Prefer dispatch by primitive type code. - Avoid uncommon traps. Methods with rarely-taken branches that throw exceptions (even caught exceptions) accumulate “uncommon trap” markers that can trigger deoptimization. The forbidden-API rule against exception construction on hot paths protects against this.
- JFR monitoring. Capture deoptimization events in production and treat them as anomalies to investigate, not routine occurrences to ignore.
NitroJEx’s posture
NitroJEx’s release process treats warmup as a deployment phase rather than an afterthought. The benchmark harness exercises every declared hot-path surface; the deterministic replay tests can replay recorded sessions through cluster startup, which doubles as warmup; and the JFR observability layer captures compilation events alongside GC and safepoint evidence. AppCDS, training profiles, and AOT compilation are deployment-time concerns rather than spec-level commitments — the architecture provides the substrate, and operations choose which techniques to apply per environment.
The general principle: JIT optimization is a production characteristic, not a development concern. Treat the warmup profile as an artifact, capture it deliberately, persist it across restarts, and verify through JFR that the system reaches steady-state JIT compilation before it accepts production traffic.
8. Why Java for this work
A reader who has followed the architecture this far has a fair question: if zero-allocation discipline, JIT warmup, and bounded GC behavior are this much work, why not use a language without these constraints to begin with? The historical answer was C++. The modern answer is more nuanced, and worth getting right.
Disciplined Java approaches C++ for the operations trading systems actually perform on the CPU. The familiar “Java is 20-40% slower than C++” framing applies when comparing well-written C++ to typical Java. When comparing well-written C++ to low-latency Java with the discipline this article has spent ten sections detailing — zero allocation, scaled longs, primitive collections, direct buffer parsing, JIT-warmed hot paths, pinned cores, NUMA-aware allocation — the gap narrows dramatically and is often within noise on the operations a trading system actually performs: primitive arithmetic, array access, predictable branches, lock-free queue handoff. LMAX Exchange has demonstrated this at production scale; the broader low-latency Java community has published numbers in this regime for over a decade. The disciplined-Java steady state is single-digit microseconds, which is sufficient for almost all institutional workloads — market making across major venues, statistical arbitrage, execution algorithms, basis and funding-rate trading.
The modern question is not “which language,” but “which substrate runs which work.” This is the framing that a 2010s comparison of “Java vs. C++” missed and that institutional architectures in 2026 increasingly get right. A serious quant trading firm has at least two distinct compute workloads:
- CPU-bound deterministic work: the trading hot path, market-data normalization, the deterministic cluster, order management, risk gating, strategy evaluation, replay. Single-writer, ordered, bounded latency, sub-millisecond decisions. This is what the article has been describing.
- GPU-bound parallel work: Monte Carlo risk simulation, options-pricing volatility surfaces, large-scale backtest fan-out across millions of historical scenarios, neural-network-based signal generation, quant research compute. Throughput-oriented, massively parallel, latency-tolerant per-task but throughput-critical at scale.
These are different problems. They run on different physical compute substrates. They want different programming languages, regardless of what the rest of the stack looks like. CPU-bound deterministic work wants a language with strong distributed-systems primitives, mature observability, and disciplined memory management — Java’s natural territory. GPU-bound parallel work wants direct access to CUDA, ROCm, or equivalent — C++ territory, full stop, because that is what the hardware speaks.
Java wins decisively for the CPU-bound deterministic side. The case is straightforward by this point in the article: distributed-systems primitives that don’t exist with the same maturity elsewhere (Aeron Cluster’s Raft-replicated deterministic state machine, Artio’s high-performance FIX engine, Agrona’s lock-free data structures, Real Logic’s SBE codec generator), best-in-class production observability (Java Flight Recorder, JMH with -prof gc, deoptimization tracking, mature profilers — genuinely without peer in the C++ or Rust ecosystems), single-writer enforcement that the JVM and the surrounding tooling make natural, and an engineering hiring pool dramatically larger than the C++ low-latency talent pool. These advantages compound in maintenance: refactoring across a Java codebase costs less engineering time than refactoring equivalent C++, and trading platforms refactor constantly as venues, strategies, and regulations evolve.
C++/CUDA wins decisively for the GPU side, and that’s not a Java weakness — it’s a hardware reality. There is no Java answer for serious GPU compute at institutional scale. Aparapi and TornadoVM exist and have their place, but neither matches raw CUDA performance for the kind of throughput a quant compute stack actually needs. The right architectural move is not to force GPU work into Java; it is to write the GPU kernels in C++/CUDA where they want to be, and architect the integration cleanly. Until recently, that integration was the painful part.
The Foreign Function & Memory API changes the integration story. This is the substantively new architectural primitive, and it deserves to be understood correctly because it is widely confused with JNI. JNI — the historical Java-to-native bridge — imposes hundreds of nanoseconds to microseconds of per-call overhead, requires reference pinning to prevent GC interference, marshals data across the boundary in ways that allocate, and has a programming model so awkward that most Java shops avoided native calls in hot paths entirely. The Foreign Function & Memory API (preview in Java 21, finalized in Java 22) is a different mechanism: it operates on MemorySegment references that point directly at off-heap or native memory without copying, calls native functions through method handles that the JIT compiles to direct call instructions, and per-call overhead drops to tens of nanoseconds. For GPU kernel launches that take microseconds anyway, FFM call cost is invisible. For CPU-side native helpers — kernel-bypass network drivers, hardware timestamp registers, FPGA control surfaces, vendor SDKs — FFM call cost is small enough that you can use native code in genuinely hot paths without disturbing the steady-state allocation discipline.
This is structurally different from “Java with a slow native escape hatch.” It is “Java architecture with native code at near-native call cost, applied at the specific points where native code earns its keep.”
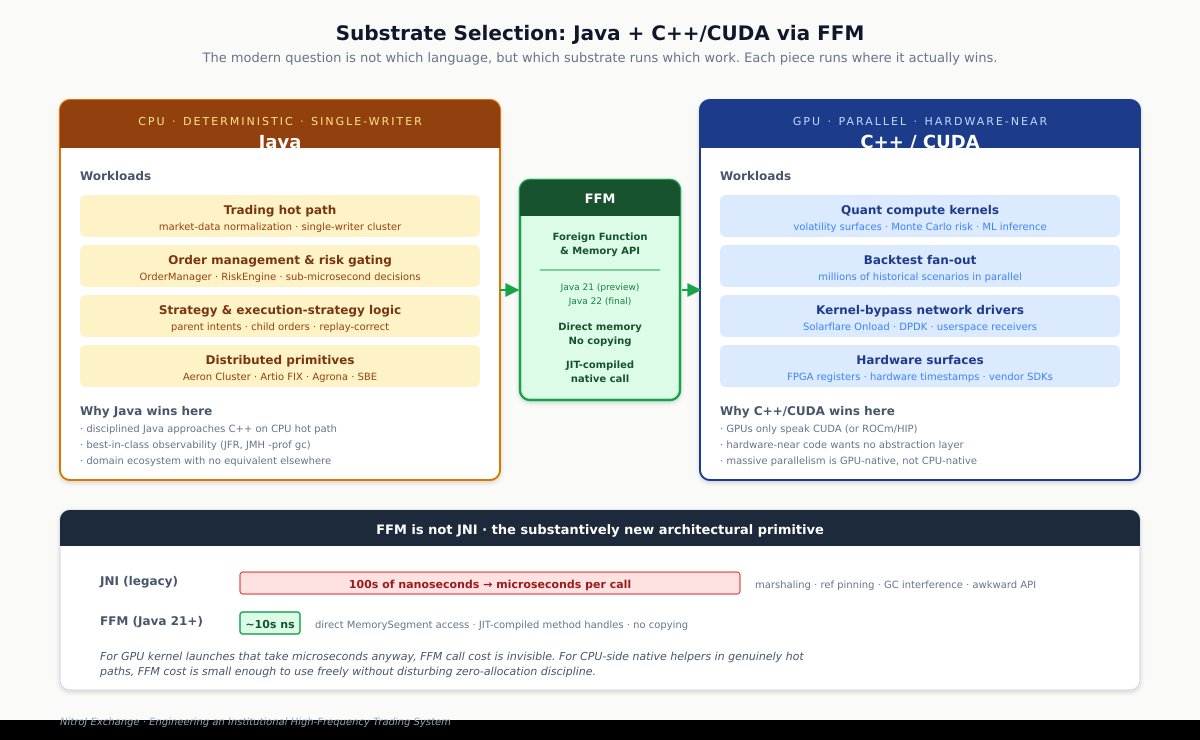
The architect’s sweet spot. Put together, the modern institutional architecture is not “choose one language” but “architect the system across the right substrates”:
- Deterministic trading cluster, strategy logic, order management, risk engine, replay infrastructure: Java, because Java’s discipline plus ecosystem wins for this work.
- Hardware-near integrations (kernel-bypass NICs, hardware timestamps, FPGA surfaces): C++ via FFM, because some operations belong as close to the metal as possible and FFM removes the historical reason to avoid them.
- Quant compute kernels (volatility surfaces, risk Monte Carlo, backtest fan-out, ML inference): C++/CUDA via FFM, because GPUs speak CUDA and that’s the only sensible answer.
Each piece runs where it actually wins. The boundaries are designed deliberately. FFM connects them at near-native cost. This is a structurally different pitch from “use Java unless you need C++” — it is “Java is the architectural substrate, and native code lives at well-chosen boundaries where it earns its place.”
Honest counterargument. Rust deserves serious consideration for new builds on the CPU side. It offers memory safety without GC, predictable performance characteristics close to C++, an increasingly capable async ecosystem, and the same kind of cheap CUDA bridge through cudarc and similar libraries. Where Rust loses to Java today is the trading-domain ecosystem: there is no Aeron Cluster equivalent in Rust, no Artio equivalent, no SBE equivalent at the same maturity level. Building those from scratch is a multi-year investment before any trading logic gets written. A Rust-native institutional trading platform is plausible and will likely emerge over the next decade; it is not a same-effort alternative to Java today.
Summary. The institutional question is not “what is the fastest language” but “what architecture gives the team the best balance of correctness, observability, distributed-systems primitives, native-code integration, and operational maturity for the workloads we actually run.” Disciplined Java approaches C++ on the CPU work that defines the deterministic trading hot path. C++/CUDA dominates the GPU work that defines the quant compute side. FFM connects them at near-native cost without the historical JNI tax. The architect picks the substrate per workload, the platform absorbs both, and the result is a system that wins at each piece rather than compromising globally. For most institutional trading work, this is the right architectural answer — and Java with the discipline this article describes is the credible foundation for it.
9. Hardware, OS, and threading: the layer beneath the JVM
Above this layer is application-level allocation discipline. Below it is a layer where institutional shops invest serious engineering effort, and where the difference between “low-latency Java” and “institutional-grade low-latency Java” is most visible. Most articles skip this layer entirely. They shouldn’t, because no amount of clever Java fixes a poorly tuned host.
The Disruptor: not just a queue
The Disruptor is the foundation of NitroJEx’s gateway-to-cluster handoff and one of the canonical low-latency patterns in Java. It deserves treatment beyond “we use it for the queue.”
A Disruptor is a single ring buffer, pre-allocated at startup with fixed capacity, where producers and consumers coordinate exclusively through monotonically increasing sequence numbers. There are no locks, no allocation per event, no wait/notify, and no volatile writes beyond the sequence updates themselves. The producer claims the next slot by atomically advancing its sequence, writes the event data into the slot in place, and publishes by updating the published sequence with a memory barrier. Consumers track their own sequences, read events from the slots, and advance their sequences after processing. Cache-line padding around the producer and consumer sequences prevents false sharing — the most common subtle performance bug in concurrent Java code, where two unrelated variables happen to live on the same 64-byte cache line and cause spurious cache-coherence traffic between cores.
Compared to LinkedBlockingQueue: the queue allocates a node per event, takes a lock for every offer and poll, signals waiters via wait/notify, and performs no padding to prevent false sharing. A Disruptor handoff measures in tens of nanoseconds; a LinkedBlockingQueue handoff measures in microseconds, with significant variance.
Key Principle: The Disruptor is not a faster queue. It is a different data structure with different invariants — pre-allocated, lock-free, padding-aware — designed specifically so high-throughput single-writer pipelines avoid all the costs of general-purpose concurrent collections.
Wait strategies
The Disruptor’s wait strategy is one of the most consequential tuning knobs in any low-latency system. It governs how a consumer waits when no events are available:
BusySpinWaitStrategyspins continuously checking for new events. Lowest latency. Pins the consumer at 100% CPU regardless of load. Appropriate for the cluster service thread on a dedicated core.YieldingWaitStrategyspins for a configurable count, then yields. Modest latency cost. Lower CPU usage when idle. Appropriate for less critical paths.SleepingWaitStrategyspins, then yields, then sleeps. Significantly higher latency. Low idle CPU. Appropriate for non-critical paths.BlockingWaitStrategyuses a lock and condition variable. Highest latency. Lowest idle CPU. Appropriate for cold paths.
Choosing wrong is one of the more common ways teams introduce hundreds of microseconds of unnecessary tail latency without realizing it. A BlockingWaitStrategy on the cluster service thread is silently catastrophic; a BusySpinWaitStrategy on every Disruptor in the system is wasteful and produces thermal-throttling effects under load. The right answer is per-thread: spin for the critical paths, block for the cold ones.
CPU pinning and isolation
By default the OS scheduler will helpfully migrate threads across cores at unpredictable moments to balance load. For most software this is fine. For a trading system it is fatal: every migration empties the L1 and L2 caches of the destination core, producing a latency spike that looks like a GC pause but is actually a cache miss cascade.
Institutional systems pin their hot threads to specific physical cores and exclude those cores from the OS scheduler’s general pool. On Linux this is done with kernel boot parameters:
isolcpus=2,3,4,5 # exclude cores 2-5 from general scheduling
nohz_full=2,3,4,5 # disable scheduler tick on these cores
rcu_nocbs=2,3,4,5 # offload RCU callbacks elsewhere
After boot, the hot threads are pinned to the isolated cores via affinity APIs (taskset at process startup, or programmatic affinity through libraries like OpenHFT’s Java-Thread-Affinity for fine-grained per-thread control). A typical assignment for a trading platform like NitroJEx:
- Core 2: Aeron media driver thread.
- Core 3: Gateway FIX session thread.
- Core 4: Disruptor consumer thread.
- Core 5: Cluster service thread (the deterministic single-writer core).
Cores 0-1 stay with the OS, the JIT compilers, GC threads, and operator-visible processes. The hot threads run uninterrupted on their dedicated cores, with cache lines warmed and stable.

The kernel boot parameters (isolcpus, nohz_full, rcu_nocbs) exclude cores 2-5 from general scheduling, scheduler ticks, and RCU callback execution respectively. The hot threads pinned to those cores run without OS interference, with cache lines stable.
NUMA awareness
On multi-socket servers, memory access latency depends on whether the memory and the CPU are on the same NUMA node. A thread on socket 0 reading memory allocated on socket 1’s local DRAM pays a 30-50% latency penalty per access, compared to local memory access. For a hot-path operation that touches several data structures, the penalty compounds.
Institutional systems pin their hot threads and their hot-path data structures to a single NUMA node. The JVM is launched under numactl --cpunodebind=0 --membind=0 to keep allocation local. Inter-thread communication structures (the Disruptor ring buffer, the cluster service’s hot state) live on the same node as the threads that access them. For a single-socket system this is automatic; for dual- and quad-socket systems it is a real configuration discipline that institutional shops always apply and most others never do.
JVM tuning
Beyond GC choice, several JVM-level options matter for steady-state low-latency operation:
-XX:+AlwaysPreTouchzeros and faults in the entire heap at startup. Without this, your first market-data burst pays page-fault latency for every previously-untouched page. With it, all faults happen during cold-path startup where they don’t matter.-XX:+UseTransparentHugePages(with kerneltransparent_hugepage=madviseset) reduces TLB misses for the heap. Significant for large heaps.-XX:GuaranteedSafepointInterval=0(with-XX:+UnlockDiagnosticVMOptions) disables the periodic timed safepoint that the JVM otherwise inserts. When you’ve proven steady-state allocation is zero and there are no operations that need a safepoint, this removes a class of microsecond-scale stalls.-XX:CompileThresholdand tiered compilation tuning matters for warmup behavior. The default tiered thresholds optimize for typical web-application workloads, which are not what you have. Custom thresholds plus a deliberate warmup phase that exercises every hot-path code shape lets you guarantee that production traffic hits fully optimized code.- JFR configuration for production observability: low-overhead settings that capture GC events, safepoints, allocation pressure, lock contention, and thread stalls without sampling overhead that would distort the latency you are trying to measure.
Kernel and OS tuning
The kernel and BIOS introduce their own latency surprises:
- CPU C-states. Disable with
intel_idle.max_cstate=0or BIOS settings. Without this, idle cores enter deep sleep states and take tens of microseconds to wake — latency that arrives at exactly the wrong moment. - Hyper-Threading / SMT. Disable on the cores running your hot threads, or pin to physical cores only. SMT introduces a class of cache-contention surprises where two threads on the same physical core compete for L1 resources unpredictably.
- CPU governor. Set to
performancemode. Frequency scaling means your CPU runs at variable clock speed; a sudden burst hits a slow CPU first and ramps up. For trading you want maximum frequency continuously. vm.swappiness=0andmlockalllock process memory. Page-fault latency from swap is hundreds of microseconds at best.khugepageddefragmentation runs in the background to compact transparent huge pages. Disable or schedule outside trading hours; it produces unpredictable pauses.- NIC tuning. Receive-side scaling, interrupt coalescing, and IRQ affinity all matter. For the most latency-sensitive paths, kernel-bypass networking (Solarflare/Onload, DPDK, or io_uring with appropriate tuning) eliminates the entire kernel network stack from the receive path.
Aeron-specific tuning
NitroJEx uses Aeron for both gateway-to-cluster transport and Raft replication between cluster nodes. Aeron has its own tuning surface:
- Media driver mode. Dedicated (own threads, own cores) is the institutional default. Shared and invoker modes save resources at latency cost.
- Term buffer length. Determines maximum unacknowledged data; too small and you stall under burst, too large and you waste memory.
- UDP receive buffer sizes. Tune at OS level (
net.core.rmem_max,net.core.wmem_max) and Aeron level. Defaults are typically too small for production trading volume. - Conductor thread pinning. The Aeron conductor coordinates the media driver; it should be pinned alongside the other hot threads.
- IPC vs UDP transport. For gateway-cluster on the same host, IPC transport bypasses the network stack entirely. For cluster-cluster Raft replication across nodes, UDP is required and the tuning matters more.
Hardware selection
Hardware choices for trading systems differ from general-purpose servers in specific ways. CPUs are chosen for clock speed and cache size over core count — a 4.5 GHz processor with 32MB L3 outperforms a 3.0 GHz 64-core processor for single-threaded hot-path work. Servers are configured for low-latency memory: often 1-DIMM-per-channel rather than fully populated, because two DIMMs per channel adds latency. NICs with kernel-bypass support (Solarflare, Mellanox ConnectX with RoCE) are standard. For co-location strategies, the closest available rack to the matching engine wins, and the shortest cable wins; institutional shops literally pay for fiber length.
This layer is where NitroJEx’s spec ends and operations begins. The architecture provides the substrate; the deployment runbook captures the specific affinity assignments, kernel parameters, JVM flags, and Aeron configuration for each environment. None of this is glamorous. All of it determines whether the system’s microsecond-scale latency claims survive contact with production.
10. Concurrency: single-writer, lock-free handoff, and the deterministic cluster
The hardware layer establishes where threads run. The concurrency layer establishes how they coordinate — and the central rule is to coordinate as little as possible. Every lock, every contended cache line, every cross-thread allocation costs latency in unpredictable ways. The two primary patterns are the single-writer principle — each piece of mutable state is written by exactly one thread — and mechanical sympathy, the alignment of data layouts and access patterns to hardware behavior.
NitroJEx organizes its runtime into two big single-writer regions connected by lock-free queues.
Gateway side. Each venue runs in its own gateway process. Inside the gateway, the FIX session reads market data and execution reports, normalizers convert them to SBE events, and a Disruptor handoff publishes events into Aeron, which carries them into the cluster. The gateway is a sequential pipeline; the Disruptor is the lock-free buffer that absorbs bursts without contention. Allocation-free under benchmark, by construction.
Cluster side. The cluster runs as a single-threaded deterministic service hosted by Aeron Cluster. All market-data updates, order state transitions, risk decisions, trading-strategy ticks, execution-strategy dispatch, parent-state transitions, and outbound order command encodings happen on the cluster thread. Aeron Cluster provides Raft-based consensus and replication, which means cluster state survives node failures and is replayed deterministically for recovery and audit.
The end-to-end path:
Venue FIX → Gateway FIX session → Normalizer → Gateway Disruptor →
Aeron cluster ingress → Cluster service (books, risk, trading strategy,
parent intent, execution strategy, child orders) →
Aeron cluster egress → Gateway order command handler →
Venue FIX order entry → Venue
Two architectural payoffs follow. First, the cluster thread sees everything in strict global order: the same market-data tick, then the same risk check, then the same trading-strategy decision, then the same execution-strategy decision, then the same child-order command. No race conditions are possible inside the cluster, by construction. Second, because Aeron Cluster persists the ingress log, the entire cluster history can be replayed against a new build to verify behavior — which brings us to determinism.
One subtle architectural rule deserves explicit treatment because the most carefully designed cluster systems get it right and most others get it wrong. It governs the ordering of state mutations and trading-strategy callbacks during execution-report processing.
The rule: when a child execution event arrives, OrderManager updates child state, then the execution-strategy engine updates parent state, then trading strategies receive their fill callbacks — and crucially, the path into the execution-strategy engine is not gated on whether the trading strategy is active. Followers and replaying nodes process the same sequence and arrive at identical parent state, even though they don’t run the trading-strategy active callbacks that might generate new intent. Market-data-driven actions, by contrast, are gated on active-leader state, because they produce child commands that only the leader should emit.
If parent state were updated only from the trading-strategy callback, a follower (which doesn’t run trading-strategy callbacks) would never update its parent state, and on failover the new leader would have a corrupted parent registry. Get this wrong and your system is “deterministic” in tests and corrupted in production.
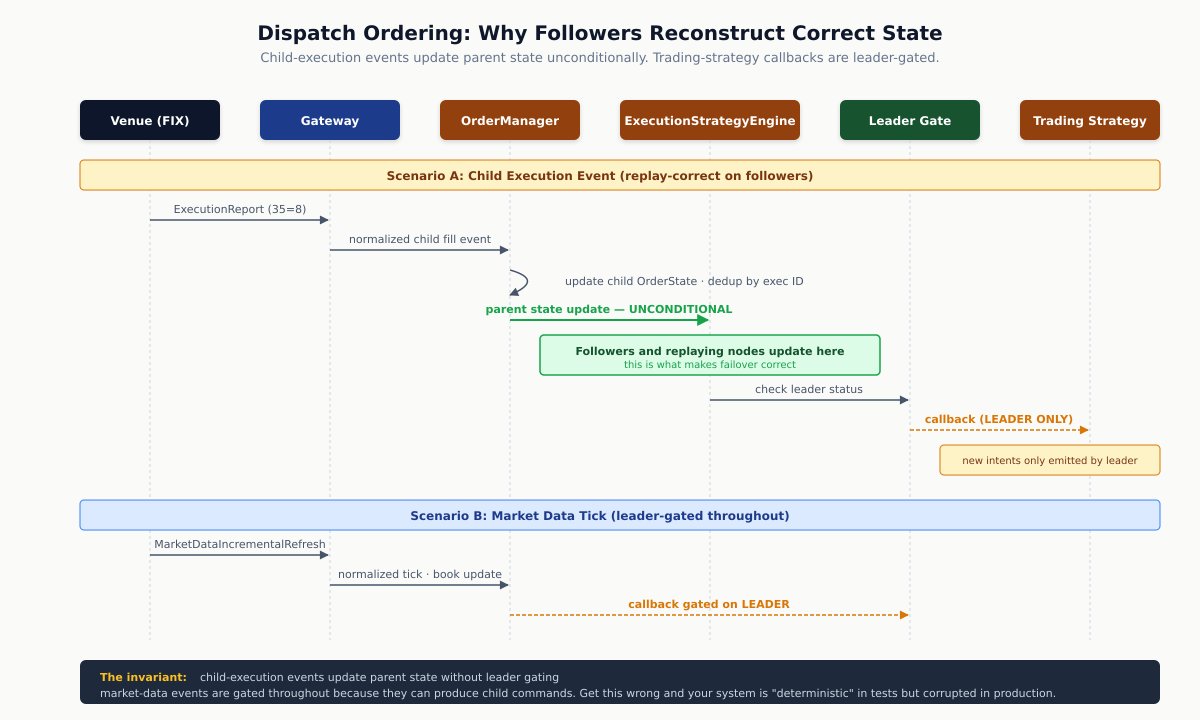
The diagram shows the rule: child-execution events update parent state unconditionally so followers reconstruct identical state, but produce trading-strategy callbacks only on the leader. Market-data events are leader-gated throughout because they can produce child commands.
Here is a more familiar visual aid in state sequence diagram with lifelines (vertical columns).
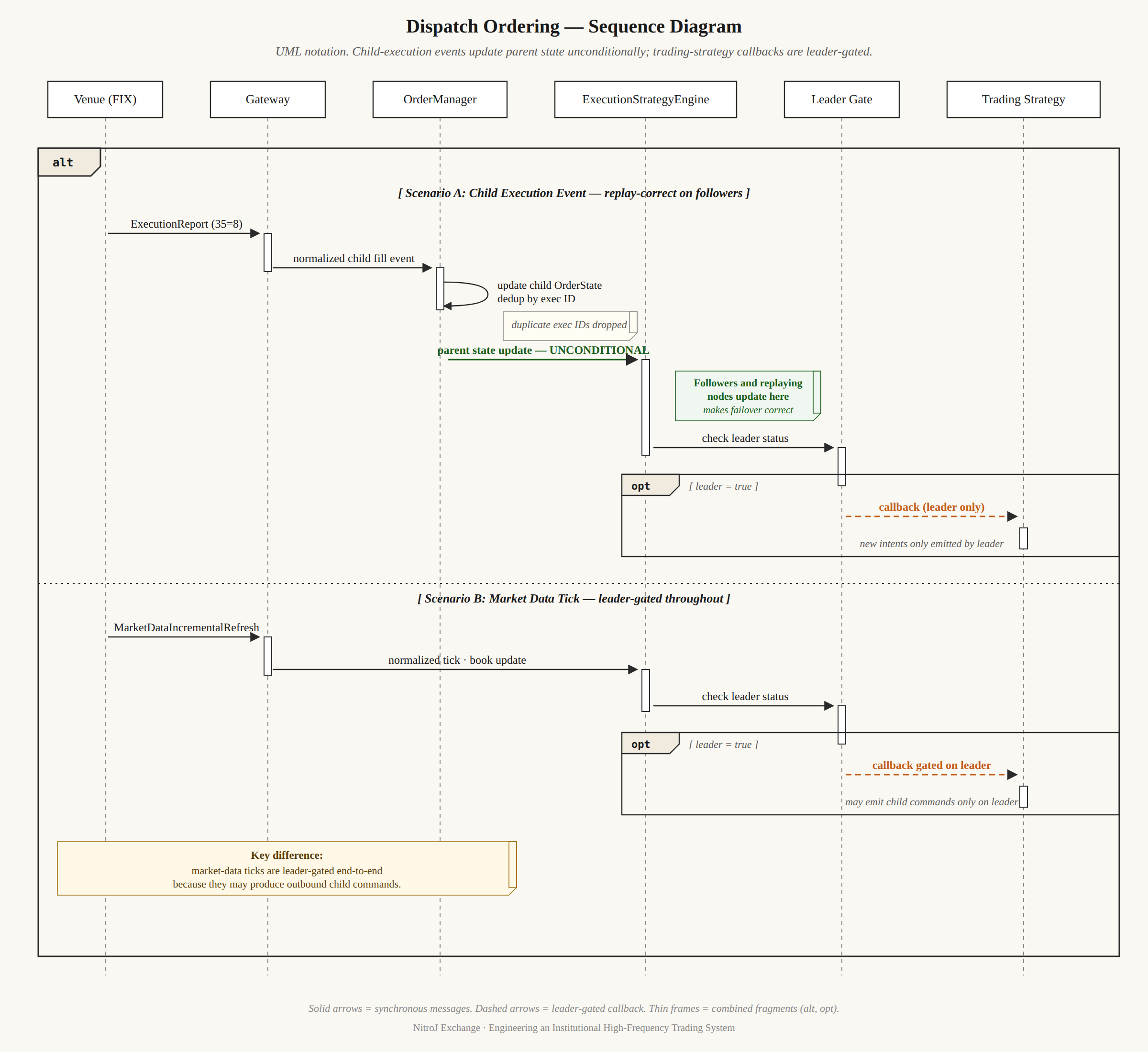
The same kind of care applies to timer correlation IDs. The discipline: register the timer correlation ID with its owning execution strategy before attempting cluster timer scheduling. If scheduling fails, roll back the owner registration. If owner registration or scheduling fails for a required timer (one whose absence would leave the parent unable to complete deterministically), terminate the parent immediately with a primitive failure reason, leaving no live child orders or active parent-child links behind. Active duplicate timer correlation IDs are rejected without replacing the existing owner. These are not optimizations — they are the ordering invariants that make distributed, replayable, recoverable trading systems work.
11. Determinism and replay
Determinism is the property that, given the same ordered input event stream and the same initial snapshot, the cluster must produce the same order state, risk state, book state, strategy decisions, parent state transitions, parent-to-child mappings, child order command sequence, counters, and outbound command sequence.
This matters far beyond academic elegance:
- Replay-based testing. You can record a real production day’s ingress log and replay it against any new build to verify that strategy and risk behavior are unchanged.
- Bug reproduction. When a bug fires in production, you replay the exact event sequence in a test environment and step through it.
- Cluster recovery. A node that has fallen behind rebuilds its state by replaying the ingress log from the last snapshot.
- Audit defensibility. A trading firm under regulatory inquiry produces a deterministic, replayable account of every decision the system made.
The discipline determinism imposes is significant. Strategies must not call System.currentTimeMillis() directly — time enters as a normalized event and is read through the deterministic cluster clock. Strategies must not consult external services synchronously — those calls happen in the gateway and arrive as events. Strategies must not branch on thread-local state or random numbers without seeding — randomness, if needed, comes from a deterministic seed that is part of the replayable input.
NitroJEx’s replay test surface is broad: L2 market data, L3 market data, L3-to-L2 derivation, execution reports, duplicate execution reports (the idempotency guarantee), order rejects, risk rejects, strategy-generated orders, timer-driven strategy behavior, snapshot/load/replay, parent state transitions, parent terminal reason codes, parent-to-child mappings, child order command sequences, parent timers, and counters. The replay test does not check only the final state; it checks the entire ordered sequence of decisions.
A pattern worth highlighting that NitroJEx does not currently ship but real institutional systems often do: dual-execution shadow mode. A candidate build replays the live ingress stream alongside production and the two are compared event-by-event for divergence. Any divergence is a bug — either the candidate or the production system has nondeterministic behavior. Any system with a deterministic core, an ordered ingress log, and snapshot/load support has the substrate for this; adding a divergence detector is a small addition relative to the value it provides for production cutover decisions.
The discipline determinism imposes looks annoying when you are writing a strategy and want to “just” log the wall clock or read a config file. It is the price of a system that can be audited, replayed, and trusted.
Key Principle: Trading firms that cannot replay their own behavior have, in practice, given up on understanding their own losses.
12. Benchmarking as architectural contract
Most systems treat benchmarking as a measurement activity: write the system, measure how it performs, report the numbers. Institutional trading systems treat it differently.
Key Principle: Performance characteristics are correctness properties, and benchmarking is the mechanism by which those properties are continuously verified. A regression in
B/opis not a performance issue; it is a correctness failure.
This reframing matters because it determines what you do when a benchmark regresses. If benchmarks are measurement, a regression is a “performance issue” — interesting, worth investigating, possibly something to fix later. If benchmarks are architectural contracts, a regression is a build break — the system has lost a property it was required to maintain, and the change that introduced the regression cannot be merged.
NitroJEx maintains a release-evidence stack that operates on this premise:
- JMH benchmarks with
-prof gcoutput, archived as JSON artifacts producingB/op, allocation rate, GC count, and GC time per declared hot-path surface. Hot paths must report0 B/op(or single-digit-bytes-per-operation) after warmup under documented capacity limits. A non-zero allocation has owner, reason, path classification, and remediation task — or the zero-GC claim is blocked. - ArchUnit tests providing static guardrails against forbidden hot-path APIs. A future PR that introduces
String.formaton the hot path fails the build, regardless of whether anyone runs a benchmark. - JUnit covering correctness, deterministic replay, simulator/live-wire flow, counter behavior, and failure paths.
- JFR for longer simulator and live-wire runs where system-level evidence (GC events, safepoints, allocation pressure, lock contention, stalls) matters.
The release checklist explicitly blocks zero-GC claims unless all four classes of evidence are current. The professional claim is fenced: it applies only to declared steady-state hot paths under tested configuration limits, never to the entire repository. This separation of architectural claim from empirical claim is what makes the claim trustworthy.
A subtlety worth calling out: JMH alone does not prove latency under realistic conditions because of the coordinated-omission problem. When a benchmark loop’s measurement thread is stalled by a GC pause or scheduling delay, it stops sending requests for the duration of the stall and resumes — under-counting tail latency. Careful benchmark design (warmup periods that exclude cold-start effects, fixed event rates rather than back-to-back loops, p50/p90/p99/p99.9 reporting with histogram artifacts) addresses this partly. For institutional production deployment, an HDR Histogram-based observability layer with explicit coordinated-omission correction, dimensioned by gateway-receive, normalize, cluster-process, encode, and venue-ack stages, is typically expected as a complement to benchmark evidence.
13. Order routing and FIX connectivity
The FIX protocol is messy. It has multiple major versions (4.2, 4.4, 5.0, 5.0SP2, all carried over FIXT.1.1 transport), thousands of tags, dialect variations between venues, and historical baggage in field semantics. A platform that wants to add venues over time cannot afford to bake assumptions about a particular FIX version or a particular venue’s dialect into its core code.
A correct architecture isolates FIX completely from the deterministic core. NitroJEx achieves this through a multi-codec, plugin-routed gateway. Each FIX version generates its codecs into a separate package; gateway core code never imports a version-specific encoder class directly. Order routing uses a venue-agnostic adapter:
interface VenueOrderEntryAdapter {
void sendNewOrder(NewOrderCommandDecoder command);
void sendCancel(CancelOrderCommandDecoder command);
void sendReplace(ReplaceOrderCommandDecoder command);
void sendStatusQuery(OrderStatusQueryCommandDecoder command);
}
The version-specific differences — does the venue support native replace, does it require an account string, does it want a Coinbase-style STP tag — are pushed into an OrderEntryPolicy interface with hooks like enrichNewOrder(...) that the venue plugin implements. Execution-report normalization takes the same shape: a standard normalizer driven by an ExecutionReportPolicy per venue.
Beyond protocol mechanics, FIX is fundamentally a stateful synchronization protocol. Correctness includes session lifecycle (Logon/Logout), sequence number management, gap detection and recovery, resend logic, and heartbeat liveness. Failures here are not bugs but connectivity outages. NitroJEx integrates the Artio FIX engine for these mechanics and isolates session state strictly from the deterministic core: FIX session events are normalized into ordered internal events before they enter cluster state. This isolation is what allows the cluster core to remain clean and ordered while FIX itself does what FIX does.
The pattern is consistent. Wherever a venue might differ, hide the difference behind a small policy interface, and let venue-specific code provide the policy. Wherever a hot-path representation can avoid allocation, use a bounded byte/fingerprint form, and prove it with benchmarks.
14. Risk: the engine that says no
A properly designed institutional trading system has a risk engine that sits on the critical path of every outbound order. The risk engine’s job is to refuse trades that would breach configured limits, regardless of what the strategy thinks it wants to do. It runs on the same deterministic cluster thread as OrderManager, PortfolioEngine, and the strategy engines.
The non-negotiable properties of an institutional risk engine:
Pre-trade, not post-trade. The check happens before the order leaves the cluster, not after. A risk engine that runs as a separate service polling positions is not a risk engine; it is a reporting tool.
Bounded and fast. The check must be sub-microsecond after warmup — no allocation, no I/O, no database lookup. State lives in memory. Reject reasons are codes, never formatted strings. NitroJEx’s RiskDecisionBenchmark puts approved decisions at roughly 43 million operations per second per thread with negligible allocation rate — bounded and fast in the literal sense.
Configurable per instrument, per venue, per strategy. Position limits, notional limits, order-rate limits, max order size, fat-finger price collars, and per-strategy capital allocations should be expressible without code changes.
Authoritatively driven by execution reports. Position updates come from ExecutionReport only, never from market data or strategy intent. Same principle as the state separation discussed above: own-state is execution-report-derived.
Equipped with a kill switch with fast escalation paths. Operations must be able to halt all trading, on all venues, instantly. Specific failure paths trigger the kill switch automatically: hedge rejection during multi-leg arbitrage, child orders whose parentOrderId does not match an active parent (unreconciled risk), and exceptional venue-degradation conditions. A kill switch that cannot be exercised in under one second is not a kill switch.
Areas where institutional-grade risk goes further than basic position limits, all of which fit cleanly into the same layer:
- Cross-strategy aggregate exposure. Each strategy’s position and notional add up to firm-level exposure that must also be checked. A strategy that respects its own per-instrument limit but combines with others to exceed firm aggregate limits is not safe.
- Venue-level exposure caps with automated reduction. If a venue is misbehaving (stale data, slow acks, intermittent rejects), automated controls should reduce exposure at that venue before operator intervention.
- Order-rate limits per strategy. Both as a runaway-strategy guard and as a venue-API-quota guard. Cheap to add as a token-bucket inside the risk engine.
Risk-engine work is not glamorous. It is what determines whether the system is one configuration mistake away from an unbounded loss.
15. Order state machine correctness
The order lifecycle is where many trading systems break — not in the trading logic, but in the state-machine bookkeeping. Real systems must handle partial fills, cancel-fill races, replace semantics, rejects, and duplicates correctly under every interleaving the venue can produce.
Two state machines run in parallel. The child-order state machine transitions only on execution reports from the venue. The parent-order state machine (per parent intent) transitions on child-execution events, parent timers, and explicit parent-cancel commands.
The child state machine’s invariants must never be violated, regardless of message ordering:
- Cumulative consistency:
cumFillQty + leavesQty == orderQtyfor every state where both are defined. - Monotonicity:
cumFillQtynever decreases.leavesQtyonly decreases (never increases) except on a successful replace. - Fill bound:
cumFillQty ≤ orderQtyalways. - Status legality: the state machine has documented legal transitions. An illegal transition (e.g.,
FILLED → PARTIALLY_FILLED) is dropped through a counter and treated as a venue-protocol violation. - Idempotency: the same execution report applied twice produces the same final state, by exec-ID dedup.
- Replace-chain correctness: the chain linkage from old order to replacing order is consistent; cancel-on-replace and replace-then-cancel races are explicitly tested.
The parent state machine adds its own:
- Parent fill aggregation matches the sum of accepted child fills.
- Parent terminal events are emitted exactly once per parent.
- A child whose
parentOrderIddoes not match an active parent triggers the kill switch. The parent state machine does not silently absorb orphaned children. - Parent state survives child rejections without corruption — a rejected child does not leave the parent in an inconsistent state.
NitroJEx’s parent state machine is explicit:
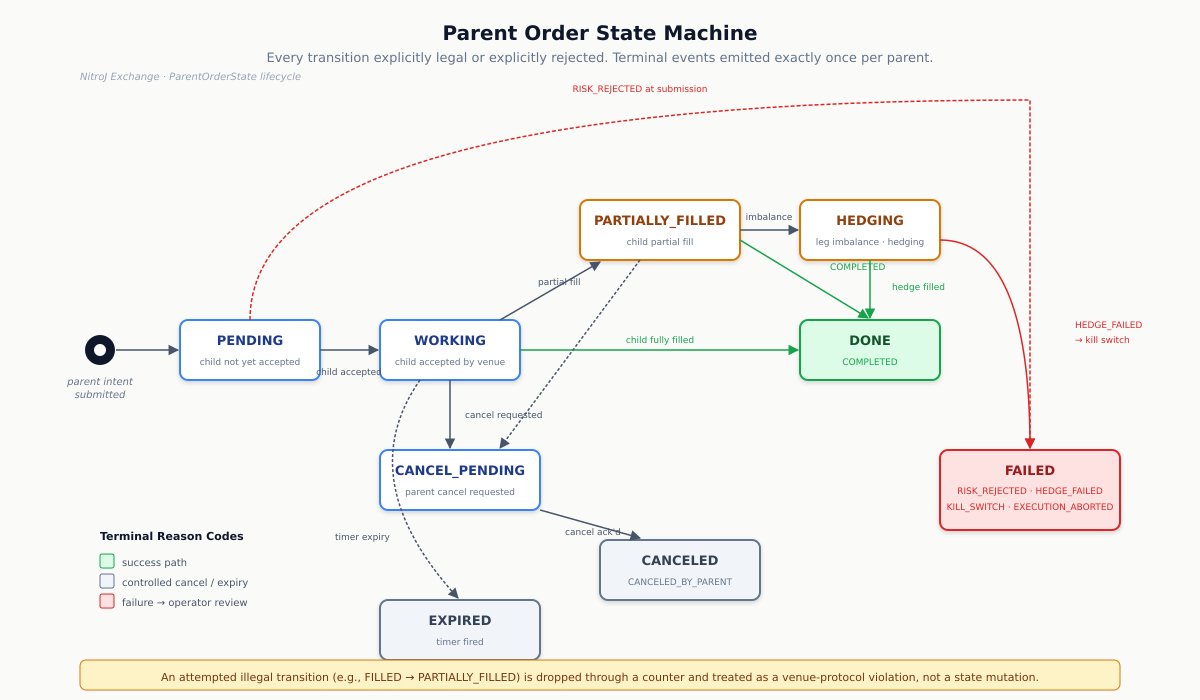
Terminal reason codes for each terminal state: COMPLETED, CANCELED_BY_PARENT, EXPIRED, RISK_REJECTED, HEDGE_FAILED, KILL_SWITCH, EXECUTION_ABORTED. Every transition is explicitly legal or explicitly rejected; an attempted illegal transition (such as FILLED → PARTIALLY_FILLED) is dropped through a counter and treated as a venue-protocol violation.
The state machine above shows all possible parent lifecycles as a static graph. To complement that view, here is one representative trajectory through the same machine drawn as a sequence diagram — the multi-leg arbitrage path with leg imbalance, hedge submission, and successful completion. Multiple trajectories are possible; this one exercises the most interesting transitions (PARTIALLY_FILLED → HEDGING → DONE) and shows what those state changes look like as a temporal flow between participants.
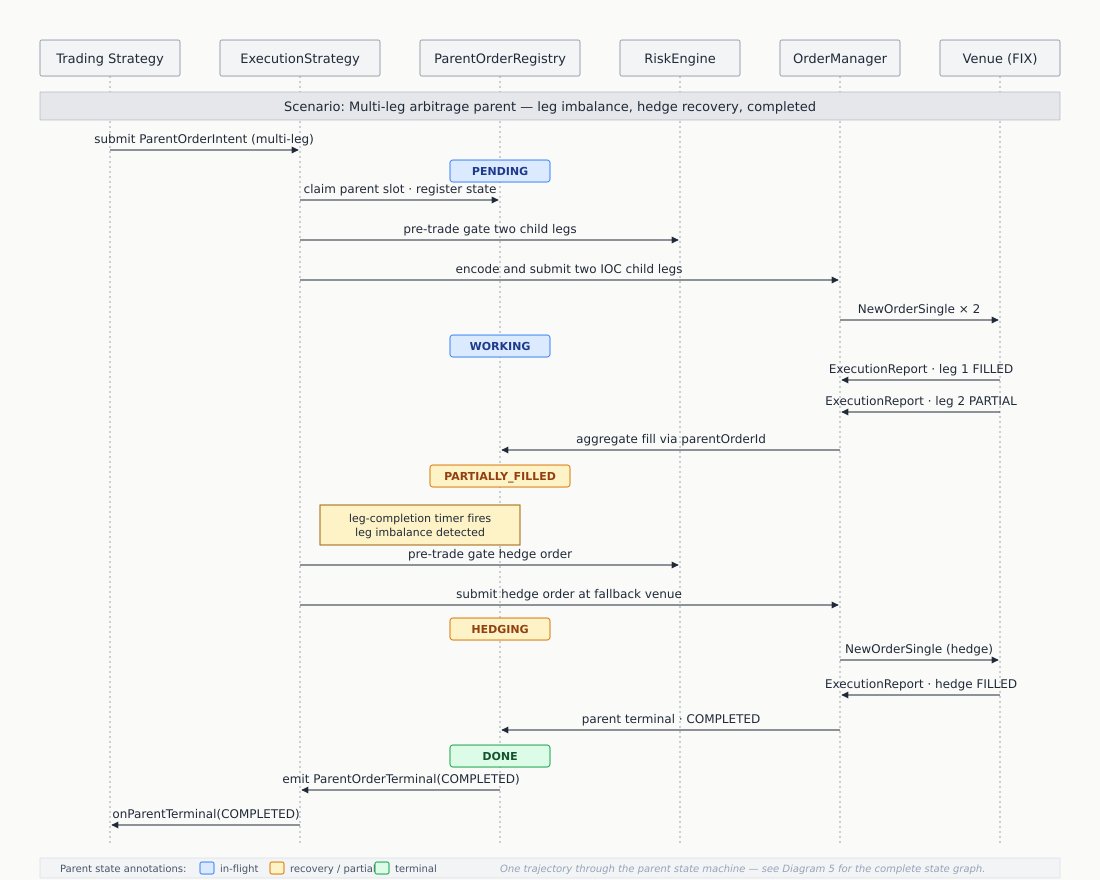
The two diagrams answer different questions. The state machine answers what are the rules of this system — a complete map of every reachable state and every legal transition. The sequence diagram answers what does one specific lifecycle look like — a temporal trace through participants for a single trajectory. Both views are useful: the state machine for verifying invariants and proving completeness, the sequence diagram for grounding the abstract graph in a concrete narrative an engineer can walk through step by step.
The wider lesson: a state machine without documented invariants is a bug surface. Documenting the invariants and testing them against every reachable state pair is one of the highest-leverage activities in trading-system development. Every transition must be either explicitly legal or explicitly rejected.
16. Testing: earning the right to connect to production
The test surface for institutional trading systems is not an afterthought; it is a defining characteristic. A serious platform requires multiple test tiers, each addressing a distinct failure class:
- Unit tests for isolated config parsing, plugin behavior, normalizer parsing, order-entry policy decisions, book mutation, consolidated aggregation.
- Integration tests for module wiring across SBE codecs, gateway normalizers, cluster market views, generated FIX codecs, and plugin composition.
- Simulator deterministic tests using a venue simulator that emits L2 snapshots and incrementals, L2 malformed messages, L3 snapshots, L3 add/change/delete sequences, sequence gaps, disconnect/reconnect, execution reports of every kind, and cancel rejects.
- Simulator live-wire end-to-end tests that start a local FIX endpoint and prove the full gateway-to-cluster-to-egress-to-gateway loop over real FIX session semantics — not just direct method calls or SBE injection.
- Deterministic replay tests that record a session, replay it from snapshot, and assert identical state evolution.
- Snapshot/load/recovery tests for cluster failover and node-rejoin scenarios.
- JMH allocation benchmarks with
-prof gcfor every declared hot-path surface. - Latency histogram and percentile tests for latency-sensitive paths.
- Static allocation scans (ArchUnit) against forbidden hot-path APIs.
The case-category coverage standard is what separates the tests you write because they are easy from the tests you write because the system needs them. Every task that owns behavior must cover positive, negative, edge, exception, and failure cases — or document explicitly why a category does not apply. Edge cases that matter include deletes for missing orders, duplicate prices across venues, snapshot followed by incrementals, L3 state recovery after bad data, parent canceled mid-flight while a child is working, child rejected with parent leftover, child filled while parent cancel is in flight, timer firing during a pending execution report, post-only reject one-tick-deeper retry, multi-leg one-leg-fill imbalance hedge, hedge rejected by risk, hedge rejection triggering the kill switch, snapshot reload mid-parent-lifecycle, capacity-full parent pool, capacity-full parent-to-child mapping, unknown execution strategy ID at startup, and incompatible trading/execution-strategy pairings.
The most important architectural commitment is the pre-production readiness gate. Real venue QA/UAT must not begin until: all unit, integration, simulator, simulator live-wire L2/L3 E2E, deterministic replay, and snapshot/load tests pass; benchmark gates publish current allocation evidence; all hot-path non-zero allocations are remediated or explicitly reclassified; and security/operations/financial-correctness preflight checks are complete. Real venue QA/UAT is for venue certification, credentials, network/TLS/session behavior, and production-readiness validation — not a substitute for local automated coverage.
This is what mature institutional trading-system testing looks like.
Key Principle: You earn the right to connect to a real venue. You do not request it.
17. Operations: secrets, configuration, recovery, observability, and runbooks
A trading platform that works in development and dies in production has not solved the trading problem; it has solved part of it. Operations is the rest, and it deserves its own architectural respect.
Secrets do not live in config files. NitroJEx’s gateway configuration stores a Vault path, not credentials:
[credentials]
vaultPath = "secret/trading/coinbase/venue-1"
The venue plugin resolves credentials at gateway startup through the configured secret source. This separation makes credential rotation possible without redeployment, makes per-environment credentials clean, and prevents secrets from sprawling into Git history.
Configuration is layered and versioned. Venue identity uses immutable numeric IDs that must not be reused, since persisted state, logs, and replay data refer to those IDs. Instrument identity follows the same discipline. Gateway and cluster configuration files define per-process binding. Per-strategy execution-strategy selection and per-instrument override are validated at startup; unknown identifiers fail before any market data is processed.
One gateway per venue. Each venue runs in its own gateway process with venue-specific startup wrappers. This isolation means a Coinbase outage does not crash the Binance pipeline, a credential rotation on one venue does not restart all venues, and per-venue capacity tuning is straightforward.
Recovery is part of the design. FIX sessions handle resend requests, sequence gaps, and reconnects. Market-data feeds recover from disconnects with explicit staleness marking. Order state survives cluster failover. The release-readiness checklist treats these as gates, not features.
Operational runbooks are first-class. A trading system without documented procedures for the failure modes that can actually happen is an experiment. NitroJEx ships explicit runbooks:
- Parent stuck. If a child is live, cancel the child before forcing the parent terminal. If no child is live and no timer can complete the parent, terminate the parent as
EXECUTION_ABORTEDand record counter evidence. If child attribution is missing or contradictory, activate the kill switch. - Child stuck. Use
OrderState.parentOrderIdas the source of truth. If the parent registry has no matching active parent, the child is unreconciled risk: keep the kill switch active, cancel the venue child if live, and reconcile balances before clearing the condition. - Hedge rejected. Any hedge rejection during multi-leg arbitrage execution is terminal parent failure. Required action: kill switch activation, venue order-status reconciliation, balance reconciliation, and strategy cooldown from the parent terminal callback.
- Post-only reject loop. Exactly one deterministic one-tick-deeper retry. More is intentionally out of scope. If rejects continue, the parent fails and operator intervention or strategy suppression decides when quoting resumes — the system does not blindly retry.
- Capacity full. Parent registry capacity, parent-child link capacity, and order-state pool capacity are hard deterministic bounds. Capacity full is a release blocker for the affected configuration unless the limit is intentionally raised and all tests, replay, snapshot/recovery, and benchmark gates are rerun.
These runbooks are short, decisive, and operationally complete. Each has explicit conditions, explicit actions, and explicit kill-switch escalations.
Observability is structured. Hot paths emit counters, not logs. Cold paths read counter snapshots and produce monitoring output. Logs are rate-limited. Metrics are dimensioned by venue and instrument so per-venue degradation does not hide in aggregate dashboards. The institutional production layer typically adds:
- HDR Histogram-based latency tracking with coordinated-omission correction, dimensioned by gateway-receive, normalize, cluster-process, encode, and venue-ack stages.
- FIX message traceability linking inbound messages to the SBE events they produced and the outbound commands those events caused, by correlation ID.
- Per-strategy and per-execution-strategy metrics: fill ratio, reject rate, parent-terminal reasons, queue-position estimate, p50/p99 decision latency, counter-derived exception rates.
- Session-level FIX metrics: gap rate, resend volume, heartbeat jitter — early-warning indicators for venue-side or network degradation that are invisible at the application metric layer.
This is unglamorous work. It is also what determines whether the platform is still running on Tuesday morning.
18. The discipline of evidence
Beneath all the specific architectural patterns is a deeper discipline that distinguishes institutional-grade engineering: rigorous separation of architectural claims from empirical claims from roadmap claims.
Most financial infrastructure marketing conflates these levels. A vendor describes a system as “designed for low latency,” “zero-GC,” and “supporting TWAP” without distinguishing which of these are architectural intentions, which are benchmark-proven properties, and which are aspirational features.
A serious project keeps the levels separate. NitroJEx’s professional claim language is precise: “designed toward low-latency deterministic hot paths” before benchmark evidence, and only after benchmark evidence is current is the stronger claim allowed: “benchmark-verified zero-allocation steady-state trading hot paths under documented capacity limits.” The roadmap is explicitly labeled as such: “This section is a roadmap catalog for future development, not a statement of current support… [items] must not be treated as implemented until a future spec, implementation plan, task cards, tests, benchmarks, deterministic replay evidence, simulator evidence, and preflight gates explicitly cover them.”
This discipline is more than honesty for its own sake. It produces tighter systems. A team that distinguishes “designed for X” from “benchmark-proven for X” will, eventually, have benchmark-proven X — because the gap between the two becomes a visible, measurable item that has to be closed. A team that conflates the levels will ship a system the first production burst destroys, because nothing forced the team to find out where the gap was.
Constraint-driven engineering — being explicit about what each release is and is not doing — produces tighter systems than goal-driven engineering alone. Every architectural document should have a “Non-Goals” section as detailed as the goals section. Every feature claim should have an evidence artifact behind it. Every roadmap item should have a clear path from candidate to implemented, with the gates spelled out.
In financial infrastructure, the truthful spec is the operational spec. Every claim you make about your system is a check that someone will eventually try to cash.
The earlier diagrams in this article each isolated one architectural concern — the hot/cold path boundary, the four-axis plugin model, state separation, CPU pinning, the parent state machine, dispatch ordering, the substrate split. Here is the system as a single picture, with every component in its proper place.
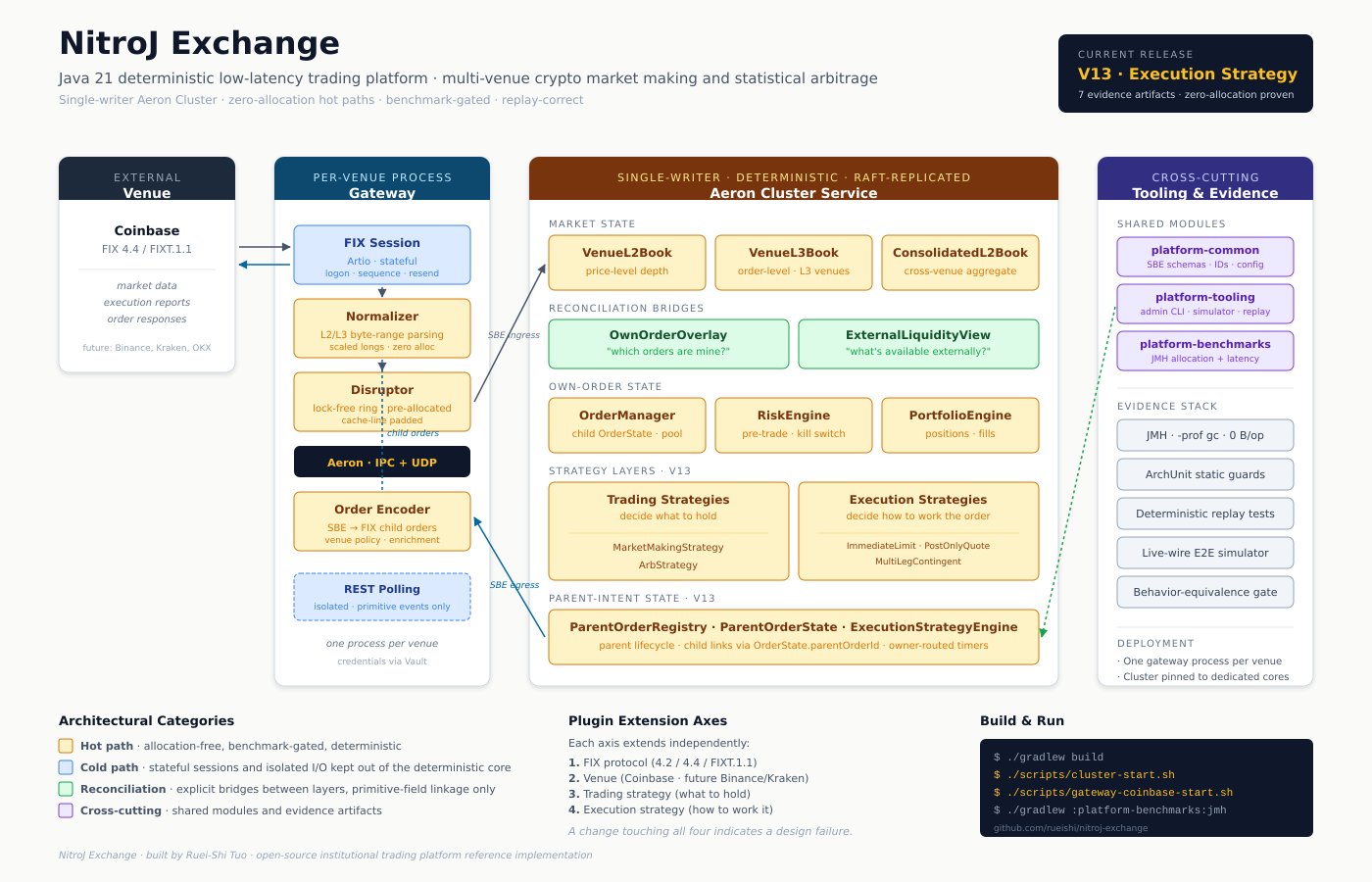
This diagram repays a longer look than the earlier ones — the density is the point. Every box on it has been discussed somewhere in the article; every relationship between boxes has been explained. What the unified view adds is adjacency — seeing which components sit next to which, which layers connect to which other layers, which concerns are cleanly separated and which are bridged by explicit reconciliation objects. The article is the case for why each piece is shaped the way it is; the diagram is the resulting system.
19. A checklist for the institutional trading platform
The questions below — drawn directly from the design tour above — are a useful audit for any system claiming institutional readiness.
Latency discipline. Have you defined the hot path explicitly, with a forbidden-API list and a required failure-reporting style? Where does cold-path data cross into hot-path code, and what enforces the boundary?
Architectural separation. Are wire protocol, venue, trading strategy, and execution strategy independent extension axes? Could you add a new venue without touching strategy code? Could you pair the same trading strategy with a different execution behavior through configuration, not code?
Market data modeling. Do you model L2 and L3 distinctly? Do you maintain per-venue and consolidated views as separate objects? Do you derive L2 from L3 deterministically? Do you model queue position for L3 venues?
State separation, idempotency, and inter-layer attribution. Is your own-order state strictly distinct from public market state? Are execution reports the only authoritative source of own-order updates? Is your parent-order state strictly distinct from child-order state? Is the link from child to parent a primitive field, never an auxiliary map? Is every event-driven transition idempotent? Do you treat unreconciled inter-layer attribution as a kill-switch condition?
Self-liquidity awareness. Does your arbitrage strategy use external executable liquidity, not gross venue liquidity? Do you have pre-trade self-cross checks? Is venue-native STP configured as an emergency brake, not the primary defense?
Strategy layering. Is “what to do” separated from “how to work the order”? Can you swap execution algorithms under the same trading intent through configuration? Do you have a behavior-equivalence gate that proves layer changes preserve prior behavior?
Memory model. Do you treat zero allocation on the hot path as a memory model rather than an optimization? Are forbidden APIs statically enforced? Do hot paths use scaled longs, primitive collections, reusable contexts, flyweight views, direct-buffer parsing, and bounded byte/fingerprint identity? Have you addressed coordinated omission in your latency reporting?
JIT warmup and AOT. Do you treat JIT warmup as a deployment phase rather than an afterthought? Does the warmup phase exercise every hot-path code shape with realistic inputs at production rates before the system accepts traffic? Do you capture warmup profiles (AppCDS, training data) for reuse across restarts? Do you monitor JFR for deoptimization events in production? Are tiered compilation thresholds tuned for the trading workload rather than left at web-application defaults?
Hardware, OS, and threading. Are your hot threads pinned to dedicated cores? Are those cores excluded from the OS scheduler? Have you configured NUMA awareness for multi-socket hosts? Are wait strategies chosen per-thread for the latency-vs-CPU tradeoff? Are JVM and kernel tuning parameters captured in deployment runbooks? Are CPU C-states, frequency scaling, transparent huge-page defragmentation, and Hyper-Threading addressed?
Concurrency model. Is your trading core single-writer? Are cross-thread handoffs lock-free and benchmarked? Is the cluster deterministic and replayable?
Determinism and dispatch ordering. Do replay tests cover market data at all depth levels, execution reports including duplicates, parent state transitions, parent timers, rejects, timer-driven behavior, and snapshot/load? Are state mutations from execution reports separated from active-leader-gated callbacks, so followers and replaying nodes reconstruct identical state? Are timer correlation IDs registered to their owners before scheduling, with rollback on failure?
Benchmarking as contract. Do you treat performance regressions as build breaks rather than performance issues? Is the JMH allocation surface tied to your release process? Are non-zero allocations remediated or explicitly reclassified before release claims?
Order state invariants. Is the child order state machine documented? Is the parent order state machine documented? Are cumulative consistency, fill bounds, monotonicity, status legality, and idempotency tested against every reachable state pair?
Risk. Does the risk engine sit pre-trade on the critical path of every child order? Is it bounded and fast, with reject reasons as codes? Is there a kill switch that operates in under a second? Are cross-strategy aggregate exposure, venue-level exposure, and order-rate limits modeled?
Testing. Do you have unit, integration, simulator harness, live-wire simulator E2E, deterministic replay, snapshot/load/replay, parent-lifecycle, JMH allocation, and latency histogram tiers? Do you require positive, negative, edge, exception, and failure coverage for every new behavior? Do you have a pre-UAT readiness gate?
Operations and runbooks. Are secrets resolved from a vault? Are venue IDs immutable? Is each venue isolated in its own gateway process? Do you have validated recovery for FIX resend, market-data gaps, order-entry edge cases, parent stuck, child stuck, hedge rejected, post-only reject loops, and capacity exhaustion? Do your runbooks have explicit conditions, explicit actions, and explicit kill-switch escalations?
Honesty. Are the claims you make about your system supported by evidence? Have you separated architectural claims from empirical claims from roadmap claims? Have you written down what your system is not yet?
Closing thoughts
The institutional high-frequency trading platform is one of the most demanding pieces of software engineering practiced commercially. It must be fast, deterministic, correct, recoverable, auditable, and maintainable across years of venue, regulatory, and strategy evolution. Every shortcut taken early — a String allocation in the hot path, a strategy that consults wall-clock time, an arbitrage that ignores its own quotes, an order manager that double-counts duplicate execution reports, a parent-state mutation gated on the wrong condition, a hot thread allowed to migrate across cores — eventually compounds into a problem that costs real money to fix and, often, real money on the way to being noticed.
The structural choices, more than any one optimization, are what separate a trading platform from a trading script:
- A clean hot/cold path boundary, statically enforced.
- Independent extension axes for protocol, venue, trading strategy, and execution strategy.
- L2 and L3 market data modeled distinctly, with explicit reconciliation against own-order state.
- Idempotent state machines connected by primitive-field attribution, never by auxiliary maps.
- A deterministic single-writer cluster with replay, snapshot, and disciplined dispatch ordering.
- A deterministic memory model where zero allocation on the hot path is enforced, not merely targeted.
- A deliberate JIT warmup phase that brings the JVM to steady-state before production traffic, with profiles captured and reused.
- A hardware, OS, and JVM tuning layer configured deliberately, with hot threads pinned and isolated.
- A pre-trade risk engine that gates every child order, with a kill switch that escalates fast.
- Documented state machine invariants, tested against every reachable state.
- Layered testing with a hard pre-UAT readiness gate.
- Operational runbooks that are explicit, decisive, and kill-switch-aware.
The discipline of evidence, more than any one architectural choice, separates a system you can run in production from one you can only run in demos. Benchmarks rather than promises. ArchUnit rather than code review. Replay rather than logging. Behavior equivalence rather than visual inspection. Each of these is a contract between the engineering team and the operating team, and each closes a category of failure that would otherwise hide until production found it.
The discipline of roadmap honesty, more than any feature catalog, separates a platform that will still be coherent in five years from one that will collapse under accumulated unfulfilled promises. Every claim must have evidence. Every aspiration must be labeled as aspiration. Every “Non-Goals” list must be as carefully written as the goals.
NitroJEx is a useful reference implementation because it gets these structural choices right and is rigorous about the boundary between what is proven and what is planned. The architecture composes — the hot/cold split, the four-axis plugin model, the L2/L3 distinction, the parent/child layering, the deterministic cluster, the deterministic memory model, deliberate JIT warmup, the hardware-aware deployment, the evidence-gated release process, the documented runbooks, the labeled roadmap. None of these are unique to NitroJEx; they are the standard moves of institutional-grade trading-system engineering. What is more rare, and worth studying, is seeing them applied together with the discipline that the whole stack actually requires.
The project’s roadmap is open and explicit. Future work documented in the repository covers algorithmic execution strategies (TWAP, VWAP, POV, implementation shortfall), additional execution algorithms (smart order routing, iceberg, bracket and OCO orders), additional trading strategies (multi-instrument and adaptive market making, statistical arbitrage and pairs trading, funding-rate arbitrage, basis arbitrage, microstructure mean reversion), additional venue integrations beyond Coinbase, and infrastructure additions like queue-position estimation views and dual-execution shadow mode. Each future capability arrives with the same evidence discipline as the existing platform: spec, implementation plan, task cards, tests, benchmarks, deterministic replay coverage, simulator coverage, and preflight gates. Nothing is “supported” until it has all of them.
NitroJEx is open source and under active development. The full source, specifications, implementation plans, migration notes, and release-evidence bundles are available at github.com/rueishi/nitroj-exchange. Engineers working on similar problems are welcome to engage — through issues, discussions, or contributions. The project is most useful as a public artifact that documents how these patterns fit together; the more eyes on the architecture, the better that artifact gets.
Get the structural choices right early. Document them honestly. Prove them with evidence. The rest of the work has somewhere solid to stand.